Totalram: 24.000 GiB
Freeram: 9.688 GiB 
Local LLMs and ellmer Extensions
Grayson White
Math 241
Week 11 | Spring 2026
Ollama

Ollama is the primary host of open-weights models
You can download these models, and then connect them to
ellmerwithchat_ollama()You can also access cloud-based models through
ollama, but these get rate-limited.
- Now, let’s talk about how to install Ollama and local models with it.
ellmer Extensions
A team at Posit has been working to make interesting
Rpackages that allow you to interact with LLMs inRToday, we’ll explore a couple of these
Rpackages


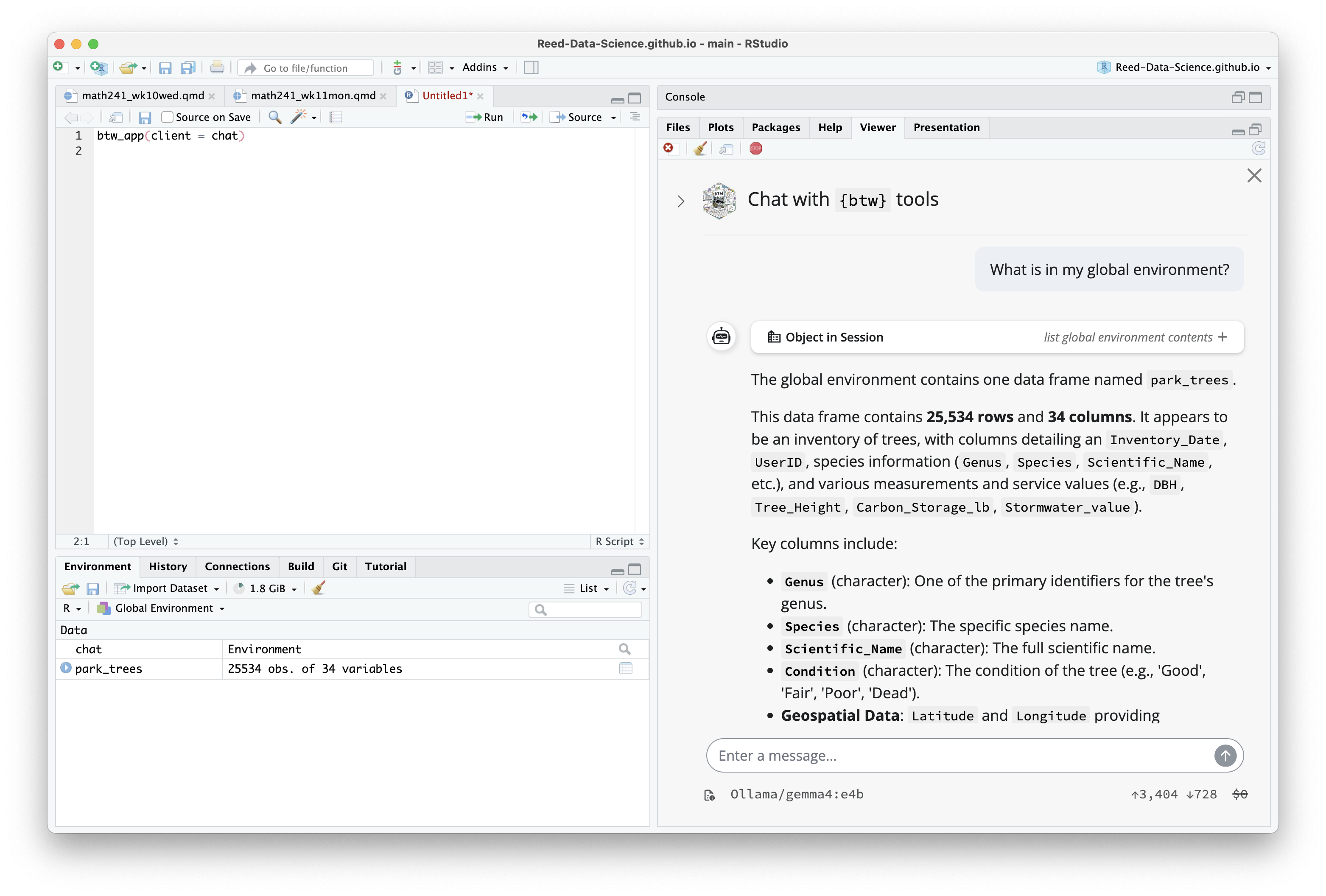
btw: Provide context to LLMs
btwprovides context about yourRenvironment to LLMs through a variety of mediums:- Quickly copy context to your computer’s clipboard,
- Through an interactive chat in your IDE, and
- In
ellmerorellmer-like chats.
There’s also an interactive IDE chat
gander
- …also provides context to LLMs in
R
gander is a higher-performance and lower-friction chat experience for data scientists in RStudio and Positron–sort of like completions with Copilot, but it knows how to talk to the objects in your R environment.
The package brings ellmer chats into your project sessions, automatically incorporating relevant context and streaming their responses directly into your documents.
- Let’s take a look!